Google Cloud Shell は、コマンドライン操作だけでなく、Python を使って Web 上の情報を取得・活用するのにも便利な環境です。
この記事では、前回インストールしたrequests ライブラリで Web ページの HTML を取得し、Beautiful Soup ライブラリでその HTML を解析して特定の情報を抽出する「Web スクレイピング」の基本的な手順を解説します。
Web スクレイピングとは?
Web スクレイピングは、Web サイトからプログラムを使って情報を自動的に抽出し、利用しやすい形に加工する技術のことです。
今回は、特定の書籍紹介ページから書籍タイトルを抜き出す例を見ていきます。
- requests: Web ページにアクセスして HTML コンテンツを取得します
- Beautiful Soup (bs4): 取得した HTML を解析し、目的のデータが含まれる要素を簡単に見つけられるようにします。
- 【Web サイトへの負荷と利用規約】
- 【HTML 構造の変化への対応】
短時間に大量のリクエストを送らない、サイトの利用規約や robots.txt を確認するなど、マナーを守って利用しましょう。
Web サイトは頻繁に更新されます。スクレイピングコードは、サイト構造が変わると動かなくなることを念頭に置き、必要に応じてメンテナンスが必要です。
必要なライブラリをインストールします。Cloud Shell ターミナルで以下のコマンドを実行してください。
pip install beautifulsoup4 --user
pipを実行した後に、ターミナル画面に以下のようなダウンロード進捗が出力されます。
すぐに終わると思いますので、少し待ちましょう。
# pip install beautifulsoup4 --user
Collecting beautifulsoup4
Downloading beautifulsoup4-4.13.4-py3-none-any.whl.metadata (3.8 kB)
Collecting soupsieve>1.2 (from beautifulsoup4)
Downloading soupsieve-2.7-py3-none-any.whl.metadata (4.6 kB)
Requirement already satisfied: typing-extensions>=4.0.0 in /usr/local/lib/python3.12/dist-packages (from beautifulsoup4) (4.12.2)
Downloading beautifulsoup4-4.13.4-py3-none-any.whl (187 kB)
━━━━━━━━━━━━━━━━━━━━━━━━ 187.3/187.3 kB 4.2 MB/s eta 0:00:00
Downloading soupsieve-2.7-py3-none-any.whl (36 kB)
Installing collected packages: soupsieve, beautifulsoup4
Successfully installed beautifulsoup4-4.13.4 soupsieve-2.7【例題】特定のWEBページから、書籍情報を抽出する
指定された URL (https://thinkr1ch.com/detail/31) から書籍情報を取得するスクリプトを作成します。
と、その前にこのWEBページのHTML構造を分析してみましょう!
今回のPythonコードが何をしているのか、一つずつ見ていきましょう。目標は、特定のWebページから「書籍のタイトル」だけを抜き出すことです。
まず、Webページって何でできてるの?(HTMLの紹介)
皆さんが普段ブラウザで見ているWebページ(例えば、Yahoo!ニュースやAmazonの商品ページなど)は、裏側ではHTMLという特別な言葉(言語)で書かれた「設計図」のようなものをもとに作られています。
- 【HTMLとは?】
- 【マークアップ言語って?】
「HyperText Markup Language」の略ですが、難しく考えなくてOKです。「Webページの見た目や構造を作るための、コンピューター用メモ帳の書き方ルール」くらいのイメージです。
日本語の文章に「ここは見出し」「ここは普通の文章」と付箋(ふせん)を貼っていくようなものです。HTMLでは、文章や画像の各部分に < > で囲まれた特別な「タグ」 という目印を付けて、「これは大きな見出しですよ (h1)」「これは段落ですよ (p)」といった意味を持たせます。
タグの役割
タグには色々な種類があり、Webページの部品を示します。
1. <h1>, <h2>, ... <h6>: 見出し(数字が小さいほど大きい見出し)
2. <p>: 段落(普通の文章)
3. <a>: リンク
4. <img>: 画像は、これも「見出し」の一種です。今回調べたいWebページでは、書籍タイトルがこの
タグの中に書かれていす。
構造(後で図解します)
HTMLでは、これらのタグが <開始タグ>内容</終了タグ> (例: <h5>スッキリわかるPython入門 第2版</h5>)という形で使われ、入れ子になったりしながら、Webページ全体の骨組み(どこに何を表示するかという構造)を作っています。ちょうど、家の設計図に柱や壁、部屋の配置が描かれているのに似ていますね。
今回やりたいこと:設計図から「タイトル」を見つける
今回のPythonコードの目的は、指定したWebページ (https://thinkr1ch.com/detail/31) の設計図(HTML)の中から、「書籍タイトル」が書かれている部分を見つけ出すことです。そして、そのページの設計図では、タイトルが <h5> タグの中に書かれていることが分かっています。
ですから、 「HTMLの中から <h5> タグを探し出し、その中身の文字を取り出す」 ことができれば、目標達成です!
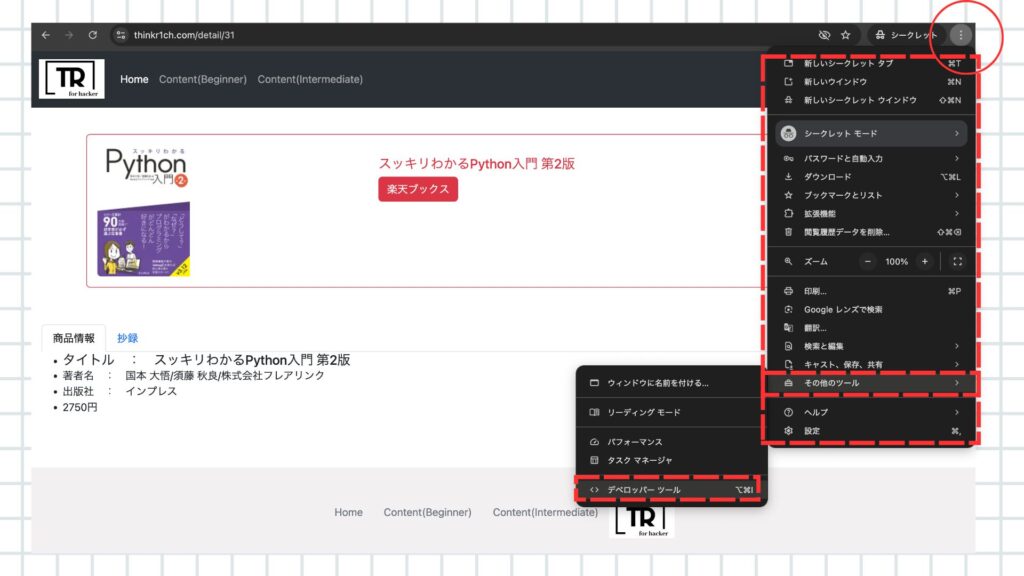
前準備①:デベロッパーツールの展開
- ご利用のWEBブラウザ(以下の画面は、GoogleChrome)を開きます。
- URLにアクセスしましょう。
- 右上の、「…」ボタンを押下します。
- 開かれたメニューから、[その他のツール]を選択してください
- 次に開かれたメニューから、[デベロッパーツール]を選択しましょう。
前準備②:HTML構造の確認
- デベロッパーツールを操作すると、左側の画面がハイライトされて表示されます。
- 該当の位置にハイライトが表示されたら、[▶︎]ボタンを押下しましょう。
- すると、以下の画像のようにHTMLの構造を掘り下げることができます。
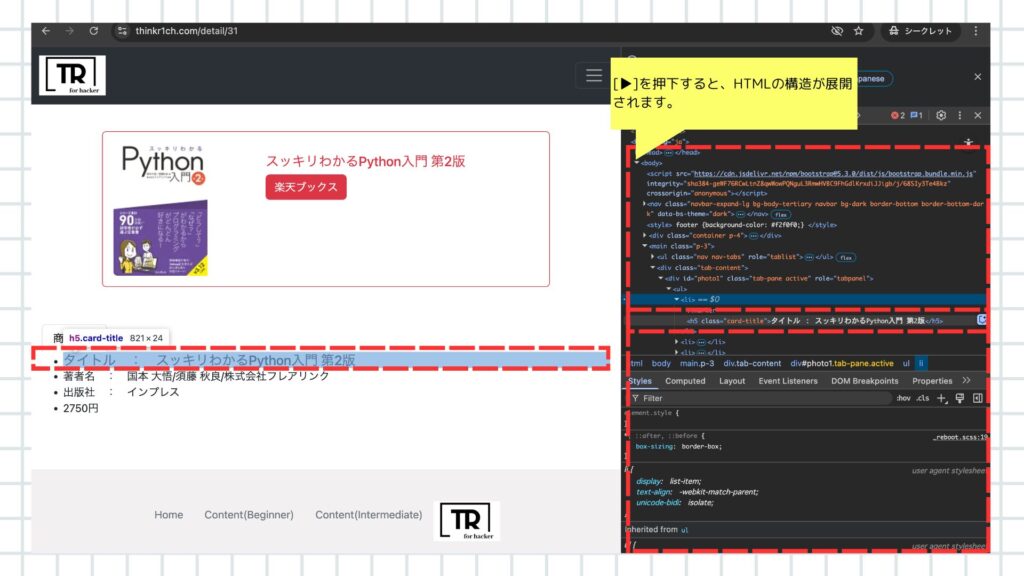
前準備③:確認結果
上記の手順により、書籍のタイトルは、<h5>タグの中にあることがわかります。
私のサーバが耐えられるか微妙なところなので、あまりやってほしくはないのですが。。。
HTMLの解析結果をもとに、Pythonコードを記述する
それではいよいよ、requests / beautiful soup を利用してスクレイピングをしてみましょう!!
(注: この ‘h5’ という指定は対象ページのHTML構造に依存します。
サイトのデザインが変わると、タイトルが見つからなくなる可能性がありますのででご留意ください。)
必要な道具 (ライブラリ)
Pythonでは便利な道具(「ライブラリ」と言います)を使います。今回は主に2つです。
- 【requests ライブラリ】
- 【BeautifulSoup ライブラリ】
Webページの設計図(HTML)をインターネット上から取ってくる係。
取ってきた設計図(HTML)を読み解いて、目的の部品(
タグ)を探しやすくしてくれる係。

ターミナルで以下のコマンドを実行しましょう。
touch scrape_book_title.py
edit scrape_book_title.pyコードを以下の通り記述します。
import requests
from bs4 import BeautifulSoup
# 対象の URL
url = 'https://thinkr1ch.com/detail/31'
print(f"Fetching title from: {url}")
try:
# requests で Web ページの HTML を取得
response = requests.get(url)
response.raise_for_status() # エラーがあればここで処理停止
response.encoding = response.apparent_encoding # 文字化け対策
# BeautifulSoup で HTML を解析
soup = BeautifulSoup(response.text, 'html.parser')
title_tag = soup.find('h5')
# h5 タグが見つかった場合のみ、その中のテキストを取得
if title_tag:
title = title_tag.text.strip() # .text でテキスト部分を取得し、.strip()で前後の空白削除
else:
title = "タイトルが見つかりません (h5 タグが見つかりませんでした)"
# --- 抽出結果を表示 ---
print("\n--- 抽出結果 ---")
print(f"タイトル:{title}")
print("-----------------")
except requests.exceptions.RequestException as e:
# Webページ取得時のエラー (ネットワークエラーなど)
print(f"\nページの取得に失敗しました: {e}")
except Exception as e:
# HTML解析中や予期せぬエラー
print(f"\nデータの抽出中にエラーが発生しました: {e}")編集の手順を忘れてしまった方は、前回の記事をご参照ください。

コード解説
- ライブラリのインポート: requests (HTML取得用)と BeautifulSoup (HTML解析用)をインポートします。
import requests / from bs4 import BeautifulSoup
これは「これから requests と BeautifulSoup という道具を使いますよ!」という宣言です。まず最初に書くお決まりの文句です。 - HTMLの取得: requests.get(url) で指定されたURLからHTMLを取得します。
ここで requests ライブラリが登場します。
requests.get(url) は、指定した url (Webページのアドレス) にアクセスして、そのページの設計図(HTMLコード)を丸ごとダウンロードしてくる命令です。
インターネットを通じてWebサーバーに「HTMLください!」とお願いしているイメージです。ダウンロードした結果(HTMLコードなどを含む通信結果)を response という名前の箱に入れています。
ちゃんとページをダウンロードできたかチェックしています。もしページが見つからなかったり、アクセスが拒否されたりすると、ここでエラーを出して処理を止めてくれます。 - 文字化け対策: response.encoding = response.apparent_encoding を入れています。
日本語のWebページだと、たまに文字が正しく表示されないこと(文字化け)があります。
これは、コンピューターが文字の種類を勘違いすることが原因です。この一行は、ダウンロードしたHTMLの文字の種類を適切に判断して、文字化けを防ぐためのおまじないです。
(ここでは詳しく触れませんが、S-JIS/UTF-8などで調べると理解が深まるでしょう。) - HTMLの解析: BeautifulSoup(response.text, ‘html.parser’) で取得したHTMLを解析可能な形にします。
ここで BeautifulSoup ライブラリの出番です。requests が取ってきたHTMLコード (response.text に入っています) は、ただの長い文字列です。このままでは、どこに <h5> タグがあるか探すのが大変です。
BeautifulSoup は、この長いHTML文字列を、タグの構造(どれがどのタグの中にあるかなど)を理解した、プログラムが扱いやすい形に 解析(整理整頓) してくれます。整理された結果を soup という名前の箱に入れています。これで、特定のタグを探す準備が整いました。 - タイトルの特定: soup.find(‘h5’) で、HTMLの中から最初に見つかる <h5> タグを探します。
いよいよ目的のタグを探します!
soup (整理整頓されたHTMLデータ) に対して、.find(‘h5’) という命令で「この中から <h5> というタグを1つ見つけてきて!」とお願いしています。
見つかった <h5> タグ(<h5 > から </h5 > まで全体)が title_tag という箱に入ります。
【if title_tag】で、ちゃんと <h5> タグが見つかったかどうかを確認しています。
もし見つかっていれば(title_tag が空でなければ)、次の処理に進みます。 - テキストの抽出: title_tag.text.strip() で、見つけた <h5> タグの中から実際のテキスト部分だけを取り出し、前後の余分な空白を取り除きます。
見つかった <h5> タグ (title_tag) の中から、実際の文字の部分だけを取り出すのが .text です。
例えば <h5> タイトル </h5> というタグなら、「 タイトル 」という文字が取り出せます。
.strip() は、取り出した文字の前後に余分な空白(スペースなど)が付いていたら、それを取り除いてキレイにしてくれる処理です。
キレイになった書籍タイトルが title という箱に入ります。 - else: title = “…”
もし if title_tag: の確認で <h5> タグが見つからなかった場合の処理です。
「タイトルが見つかりませんでした」というメッセージを title 箱に入れるようにしています。 - print(f”タイトル:{title}”)
最後に、title 箱に入っている内容(見つかった書籍タイトル、またはエラーメッセージ)を画面に表示します。
except requests.exceptions.RequestException as e: / except Exception as e: - エラー処理: try…except を使って、通信エラーや処理中の予期せぬエラーが発生した場合にプログラムが停止せず、エラーメッセージを表示するようにしています。
スクリプトの実行
作成したスクリプトを、Cloud Shell ターミナルで実行します。
抽出結果が正しく出力されれば成功です。
Rokuta@Terminal %1~ %# python3 scrape_book_title.py
Fetching title from: https://thinkr1ch.com/detail/31
--- 抽出結果 ---
タイトル:スッキリわかるPython入門 第2版
-----------------エラー画面
もしも抽出ができていない場合は、以下のようにメッセージが出力されます。
成功している方は、あえてエラーを確認してみるのもいいかもしれません。
エラーが解決しない場合は、インデントやスペルミスなどを見直してみましょう。
--- 抽出結果 ---
タイトル:タイトルが見つかりません
-----------------EOF
この記事では、Google Cloud Shell 上で Python の requests と Beautiful Soup ライブラリを使い、特定の Web ページから必要な情報を抽出する基本的な Web スクレイピングの手順を解説しました。
Web スクレイピングは強力な技術ですが、実行する際は技術的な側面だけでなく、対象サイトへの配慮や利用規約の確認も重要です。Cloud Shell を使えば、こうした処理も手軽に試すことができます。
- 【Web サイトへの負荷と利用規約】
- 【HTML 構造の変化への対応】
短時間に大量のリクエストを送らない、サイトの利用規約や robots.txt を確認するなど、マナーを守って利用しましょう。
Web サイトは頻繁に更新されます。スクレイピングコードは、サイト構造が変わると動かなくなることを念頭に置き、必要に応じてメンテナンスが必要です。