
ローカル実行で、株価のデータを取得することに成功したのでLambda関数でも実装をしていきたいと思います。
今回は、外部API(J-Quants)からLambda関数を利用して取得したデータをCSVに加工して、S3バケットに保存する。という処理を実装していきたいと思います。
まずは、Lambda関数とS3を作成していきます。
今回やりたいこと
- Lambda関数の作成
- S3バケットの作成
目次
Lambda関数の作成
①マネジメントコンソールからLambdaを検索
マネジメントコンソールにログインしてLambdaを検索します。
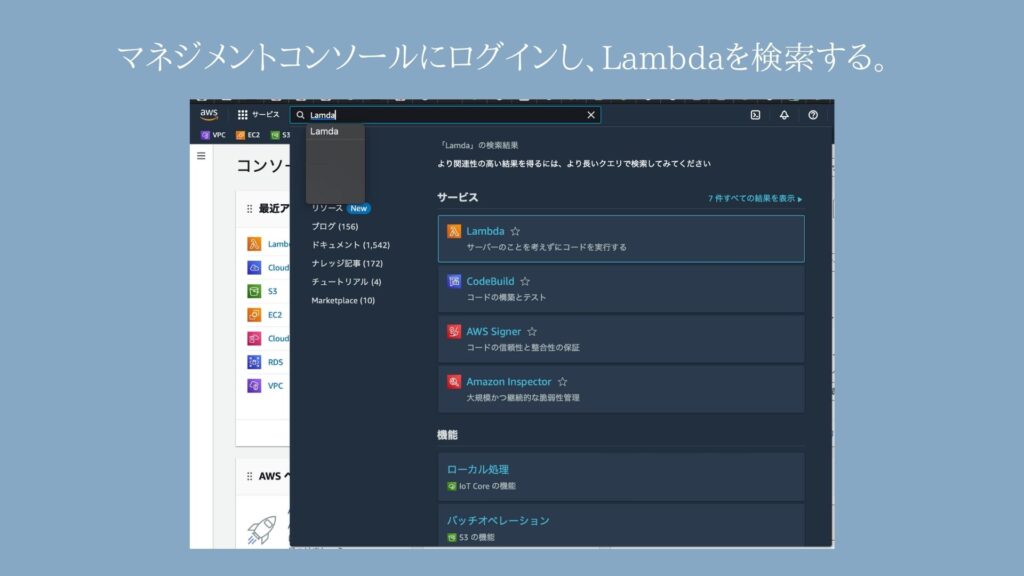
②コンソール画面から作成
Lambdaのコンソール画面が開くので、「関数の作成」ボタンを押下します。
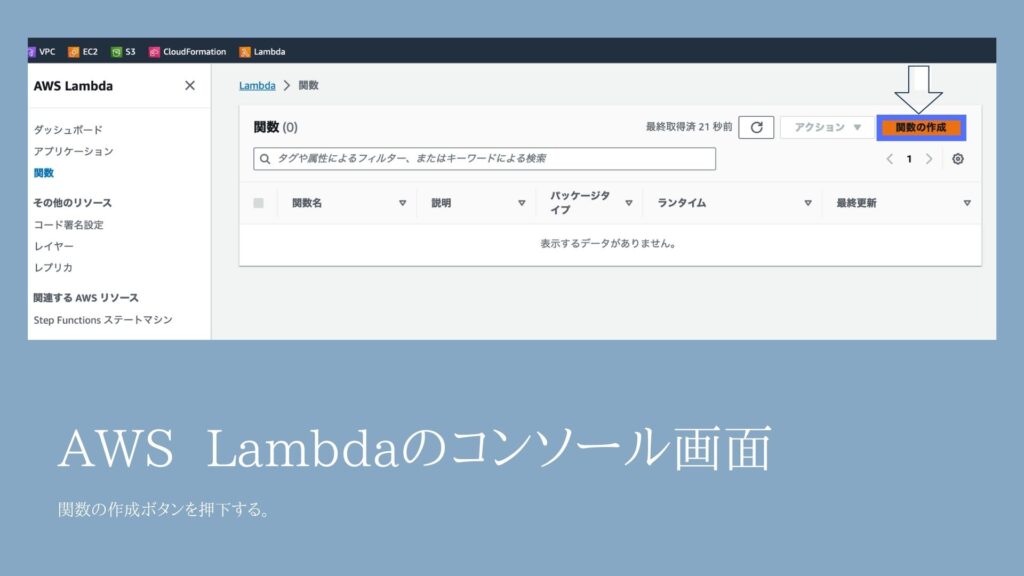
③詳細の設定画面
関数の作成画面に遷移するので、作成に必要な項目を入力していきます。
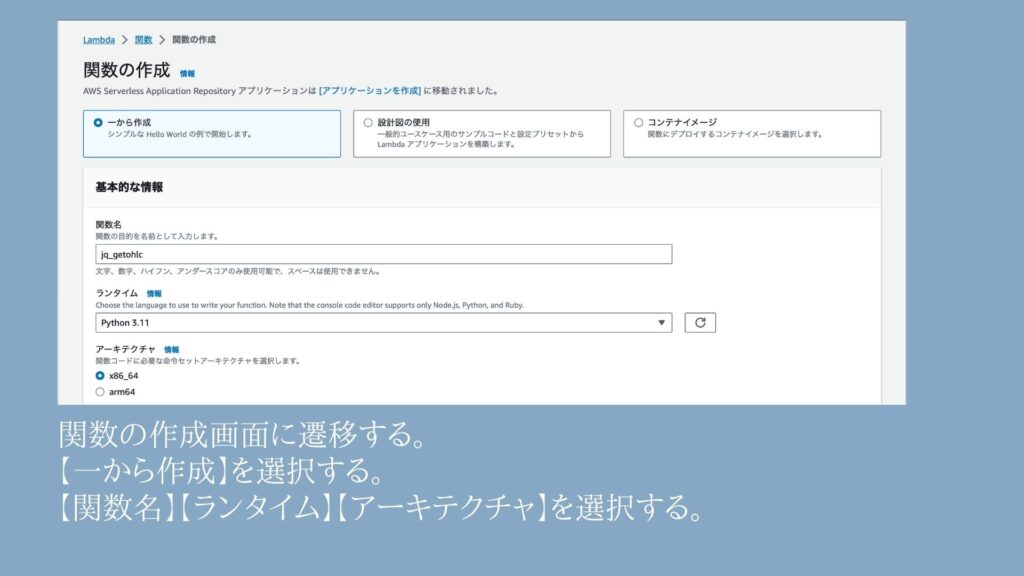
④実行ロールの変更を展開して、中身を確認
今回は、「基本的なLambdaアクセス権限で新しいロールを作成」が選択されていたのでそれを利用します。
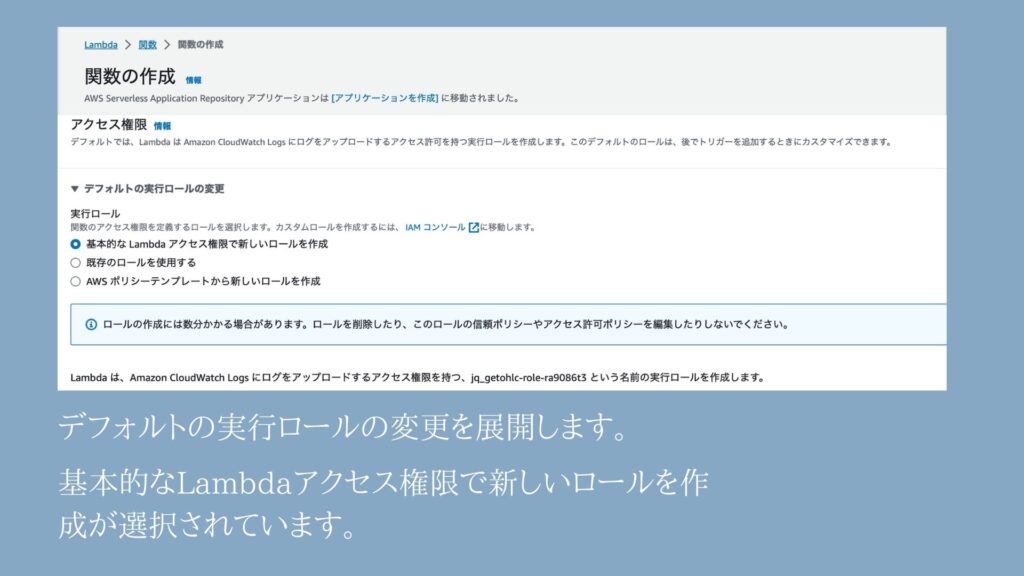
【ご参考:設計図の使用】
⑤関数作成後のイメージ
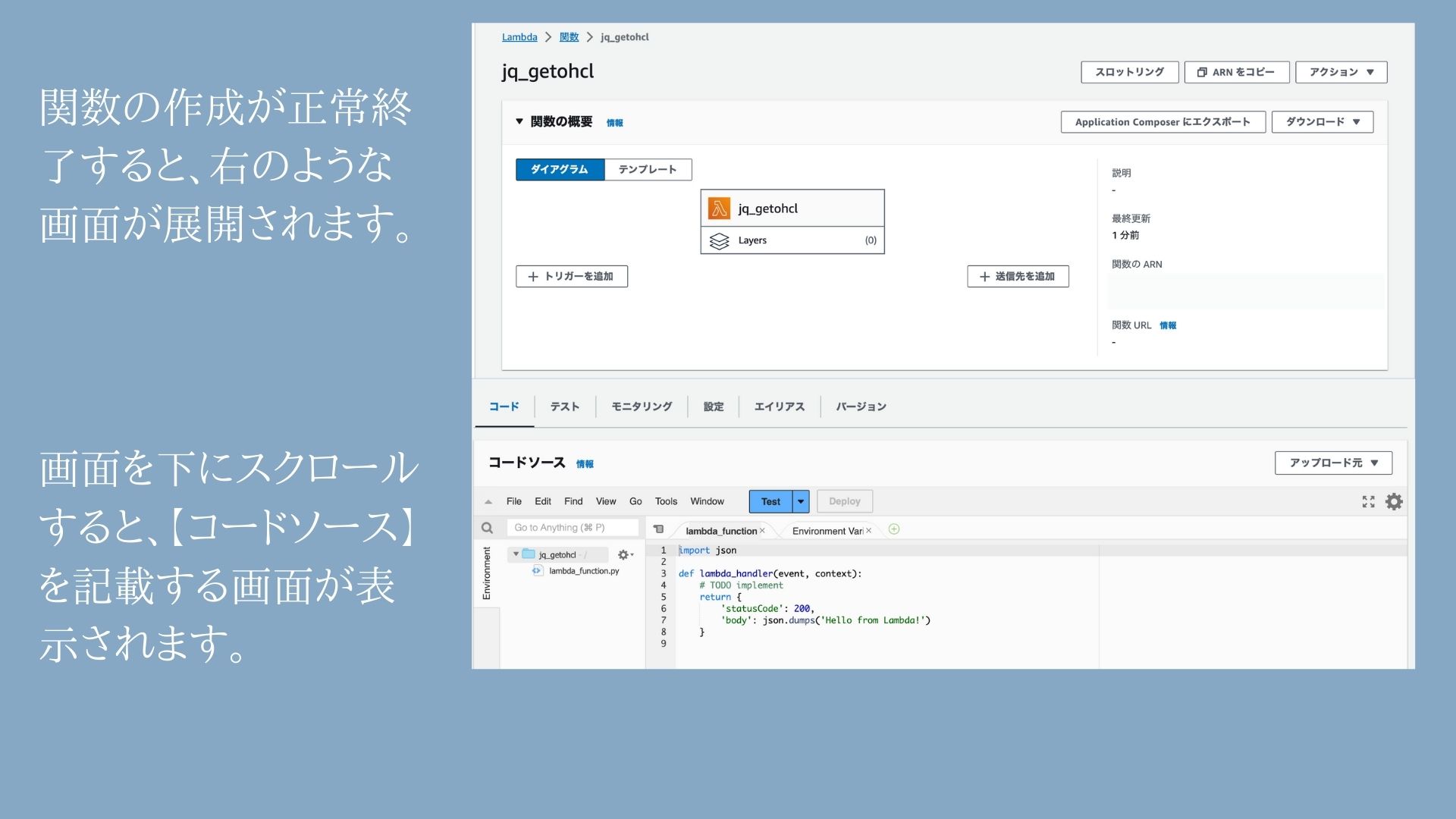
⑥コードソース欄
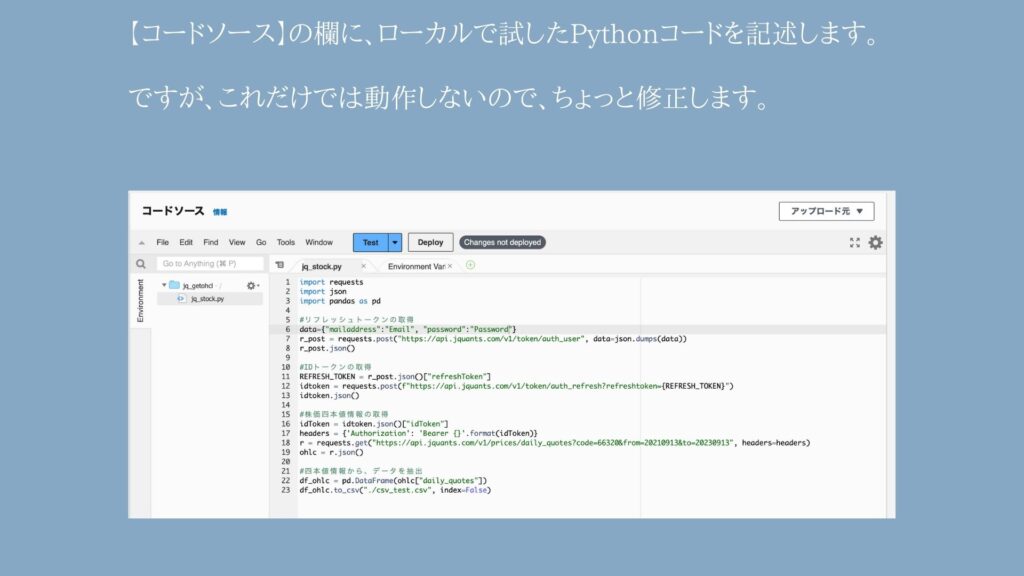

import requests
import json
import pandas as pd
import boto3
import os
def lambda_handler(event, context):
#リフレッシュトークンの取得
data={"mailaddress":"メールアドレス", "password":"パスワード"}
r_post = requests.post("https://api.jquants.com/v1/token/auth_user", data=json.dumps(data))
r_post.json()
#IDトークンの取得
REFRESH_TOKEN = r_post.json()["refreshToken"]
idtoken = requests.post(f"https://api.jquants.com/v1/token/auth_refresh?refreshtoken={REFRESH_TOKEN}")
idtoken.json()
#株価四本値情報の取得
idToken = idtoken.json()["idToken"]
headers = {'Authorization': 'Bearer {}'.format(idToken)}
r = requests.get("https://api.jquants.com/v1/prices/daily_quotes?code=66320&from=20220901&to=20230908", headers=headers)
ohlc = r.json()
#四本値情報から、データを抽出
df_ohlc = pd.DataFrame(ohlc["daily_quotes"])
#抽出したデータをCSVに変換して、/tmpに一時格納する
df_ohlc.to_csv("/tmp/jvc_stock.csv", index=False)
#/tmp領域から、S3にCSVファイルをアップロードする
s3 = boto3.client('s3')
s3.upload_file('/tmp/jvc_stock.csv', 'jq-6632jvc-ohlc', 'jvc_stock.csv')
#/tmpのCSVはゴミデータとなるため削除する
os.remove('/tmp/jvc_stock.csv')
return {
'status_code': 200
}

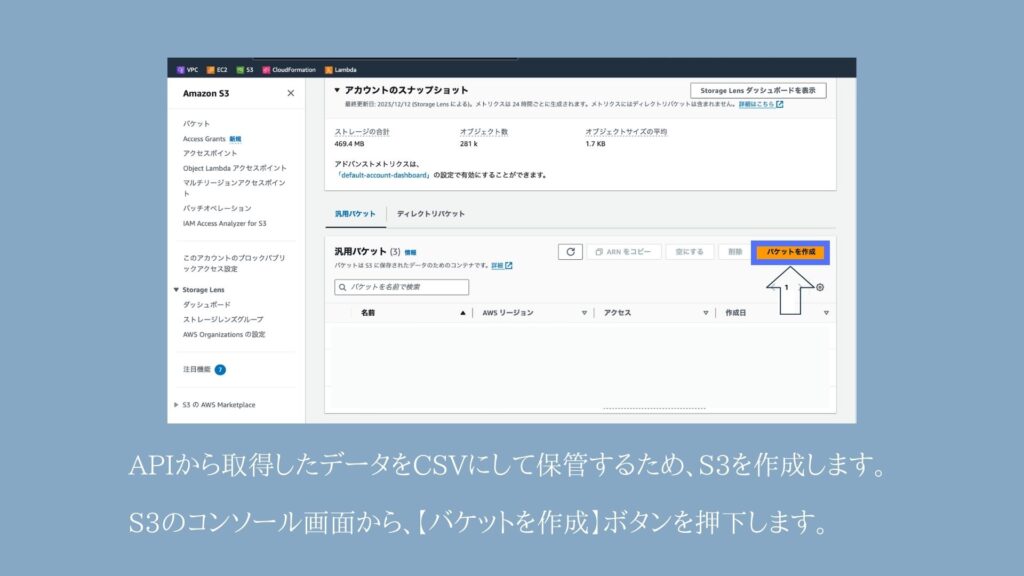
S3バケットの準備
いったんLambda関数の作成は終わったので、次はS3バケットを作っていきます。
このS3バケットに、Lambda関数で取得した株価情報CSVを格納したいと思います。
⑦S3バケットの作成
⑧バケット作成後とアクセス許可画面
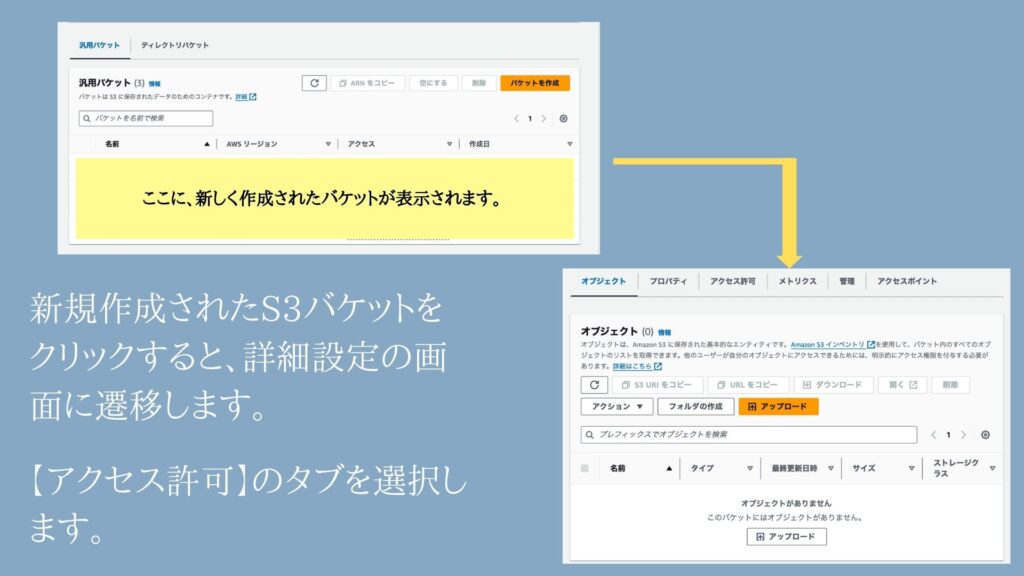
⑨アクセス許可からバケットポリシーを編集画面を選択する
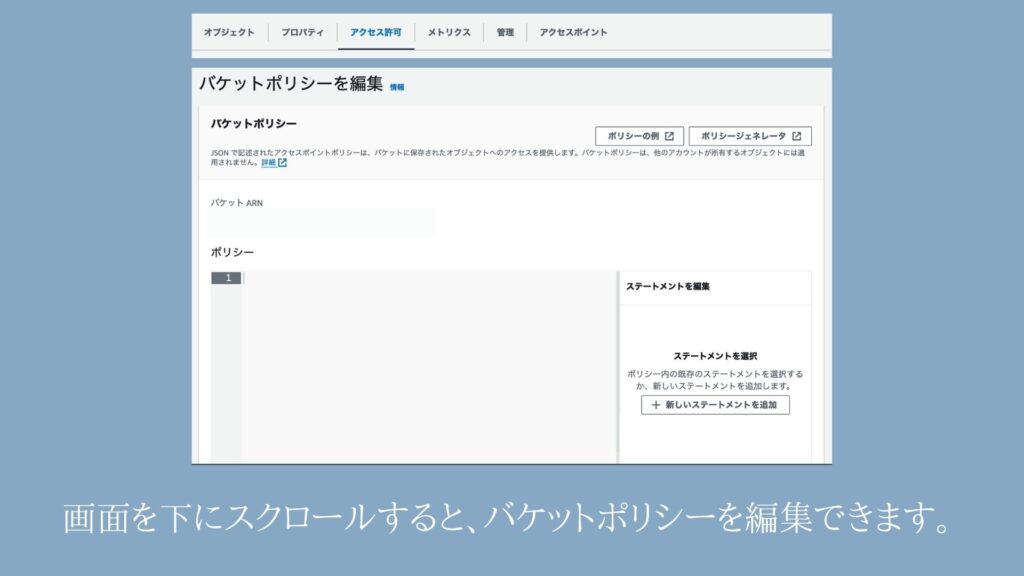
ここでバケットポリシーを編集することができるのですが、記事が長くなってきてしまったので一旦休憩させてください!
次回、Lambda関数に付与したロールのARNを取得してバケットポリシーに割り当てる。というところからスタートしていきたいと思います。
次回、Lambda関数に付与したロールのARNを取得してバケットポリシーに割り当てる。というところからスタートしていきたいと思います。
では、また次回!








ですので、関数化したりパッケージをインポートしたりして加工します。